TensorFlow笔记1-1-结构化数据建模流程范例
文章内容源于https://github.com/lyhue1991/eat_tensorflow2_in_30_days,能力有限,未做太多修改,未来会加入自己的理解。
一、准备数据
titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。
结构化数据一般会使用Pandas中的DataFrame进行预处理。
导入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models,layers
dftrain_raw = pd.read_csv('./data/titanic/train.csv') # dftrain_raw.shape:(712, 12)
dftest_raw = pd.read_csv('./data/titanic/test.csv')
dftrain_raw.head(10)
输出结果:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 493 | 0 | 1 | Molson, Mr. Harry Markland | male | 55.0 | 0 | 0 | 113787 | 30.5000 | C30 | S |
| 1 | 53 | 1 | 1 | Harper, Mrs. Henry Sleeper (Myna Haxtun) | female | 49.0 | 1 | 0 | PC 17572 | 76.7292 | D33 | C |
| 2 | 388 | 1 | 2 | Buss, Miss. Kate | female | 36.0 | 0 | 0 | 27849 | 13.0000 | NaN | S |
| 3 | 192 | 0 | 2 | Carbines, Mr. William | male | 19.0 | 0 | 0 | 28424 | 13.0000 | NaN | S |
| 4 | 687 | 0 | 3 | Panula, Mr. Jaako Arnold | male | 14.0 | 4 | 1 | 3101295 | 39.6875 | NaN | S |
| 5 | 16 | 1 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female | 55.0 | 0 | 0 | 248706 | 16.0000 | NaN | S |
| 6 | 228 | 0 | 3 | Lovell, Mr. John Hall ("Henry") | male | 20.5 | 0 | 0 | A/5 21173 | 7.2500 | NaN | S |
| 7 | 884 | 0 | 2 | Banfield, Mr. Frederick James | male | 28.0 | 0 | 0 | C.A./SOTON 34068 | 10.5000 | NaN | S |
| 8 | 168 | 0 | 3 | Skoog, Mrs. William (Anna Bernhardina Karlsson) | female | 45.0 | 1 | 4 | 347088 | 27.9000 | NaN | S |
| 9 | 752 | 1 | 3 | Moor, Master. Meier | male | 6.0 | 0 | 1 | 392096 | 12.4750 | E121 | S |
字段说明:
- Survived:0代表死亡,1代表存活【y标签】
- Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
- Name:乘客姓名 【舍去】
- Sex:乘客性别 【转换成bool特征】
- Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
- SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
- Parch:乘客父母/孩子的个数(整数值)【数值特征】
- Ticket:票号(字符串)【舍去】
- Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
- Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
- Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
数据调用:
直接通过字段名调用。
print(dftrain_raw['Survived'])
输出结果:
0 0
1 1
2 1
3 0
4 0
..
707 1
708 0
709 0
710 0
711 0
Name: Survived, Length: 712, dtype: int64
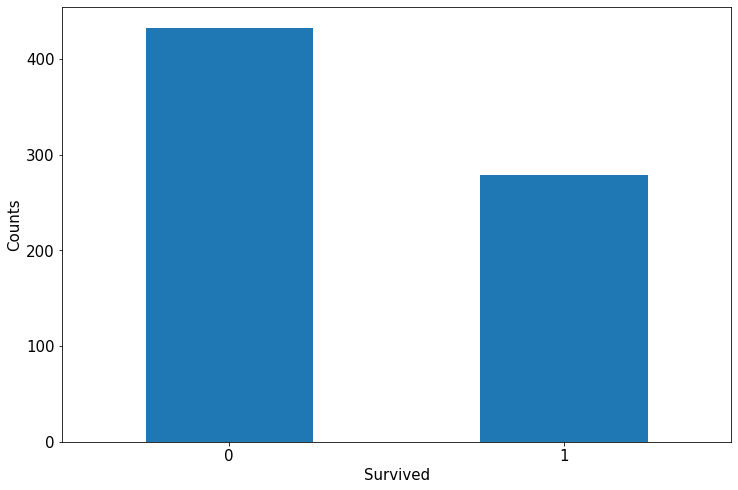
简单查看label分布情况
利用Pandas的数据可视化功能我们可以简单地进行探索性数据分析EDA(Exploratory Data Analysis)。
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',
figsize = (12,8),fontsize=15,rot = 0)
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()
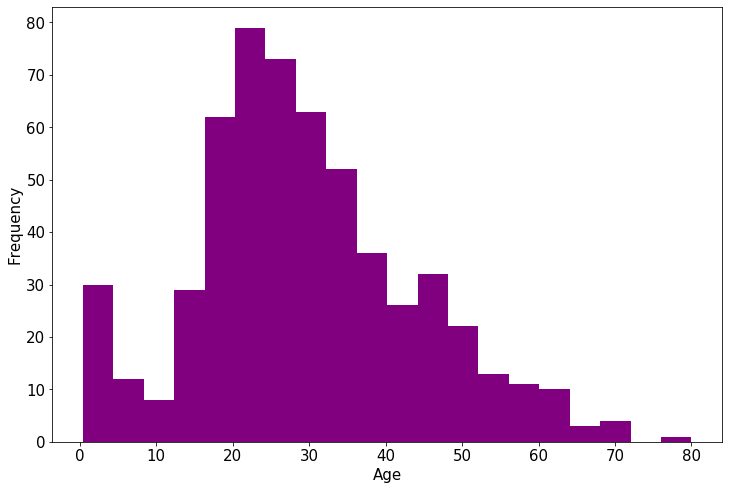
年龄分布情况
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Age'].plot(kind = 'hist',bins = 20,color= 'purple',
figsize = (12,8),fontsize=15)
ax.set_ylabel('Frequency',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()
获取满足Survived==0的字段为Name的数据项
print(dftrain_raw.query('Survived==0')['Name'])
0 Molson, Mr. Harry Markland
3 Carbines, Mr. William
4 Panula, Mr. Jaako Arnold
6 Lovell, Mr. John Hall ("Henry")
7 Banfield, Mr. Frederick James
...
706 Vander Planke, Mrs. Julius (Emelia Maria Vande...
708 Stewart, Mr. Albert A
709 Ekstrom, Mr. Johan
710 Fynney, Mr. Joseph J
711 Clifford, Mr. George Quincy
Name: Name, Length: 433, dtype: object
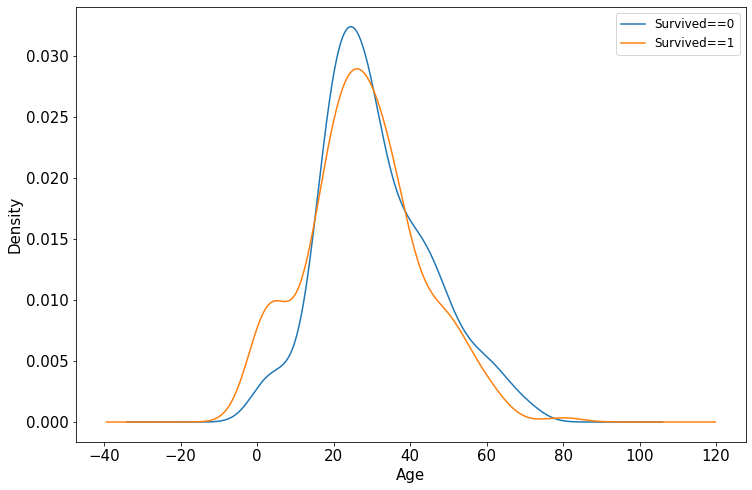
年龄和label的相关性
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw.query('Survived == 0')['Age'].plot(kind = 'density',figsize = (12,8),fontsize=15)
dftrain_raw.query('Survived == 1')['Age'].plot(kind = 'density',figsize = (12,8),fontsize=15)
ax.legend(['Survived==0','Survived==1'],fontsize = 12) # 图例
ax.set_ylabel('Density',fontsize = 15) # y轴
ax.set_xlabel('Age',fontsize = 15) # x轴
plt.show()
下面为正式的数据预处理
def preprocessing(dfdata):
# 分别对每个字段进行预处理
dfresult= pd.DataFrame() # 初始化,逐步添加处理后的数据属性
#Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
dfPclass = pd.get_dummies(dfdata['Pclass']) # one hot 编码
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ] # Index(['Pclass_1', 'Pclass_2', 'Pclass_3'], dtype='object')
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
#Sex:乘客性别 【转换成bool特征】
dfSex = pd.get_dummies(dfdata['Sex']) # one hot 编码
dfresult = pd.concat([dfresult,dfSex],axis = 1)
print(dfresult.head(3))
#Age
dfresult['Age'] = dfdata['Age'].fillna(0) # 用0填充空值
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32') # 标记空值项(astype:字段类型转换)
#SibSp,Parch,Fare:都是整数值,无缺失值,不需要处理
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin:有缺失值
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns] # 字段重命名
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
print("处理训练集数据:")
x_train = preprocessing(dftrain_raw)
y_train = dftrain_raw['Survived'].values
print("处理测试集数据:")
x_test = preprocessing(dftest_raw)
y_test = dftest_raw['Survived'].values
print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )
输出结果:
处理训练集数据:
Pclass_1 Pclass_2 Pclass_3 female male
0 1 0 0 0 1
1 1 0 0 1 0
2 0 1 0 1 0
处理测试集数据:
Pclass_1 Pclass_2 Pclass_3 female male
0 0 0 1 1 0
1 0 0 1 1 0
2 0 0 1 1 0
x_train.shape = (712, 15)
x_test.shape = (179, 15)
二、定义模型
使用Keras接口有以下3种方式构建模型:
- 使用Sequential按层顺序构建模型
- 使用函数式API构建任意结构模型
- 继承Model基类构建自定义模型
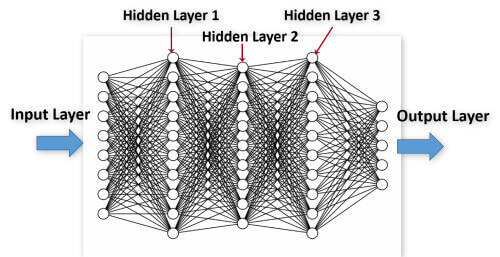
此处选择使用最简单的Sequential,按层顺序模型,一层一层往前,没有什么环的结构。比如像前馈网络那样。
keras.layers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(20,activation = 'relu',input_shape=(15,)))
model.add(layers.Dense(10,activation = 'relu' ))
model.add(layers.Dense(1,activation = 'sigmoid' ))
model.summary()
输出结果:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 20) 320
_________________________________________________________________
dense_1 (Dense) (None, 10) 210
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 541
Trainable params: 541
Non-trainable params: 0
_________________________________________________________________
注:Param = (输入数据维度+1) 神经元个数*
三、训练模型
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
# 在训练模型之前,我们需要通过compile来对学习过程进行配置
# 二分类问题选择二元交叉熵损失函数
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC']) # 优化器optimizer,损失函数loss,指标列表metrics
# fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,
# 如果有验证集的话,也包含了验证集的这些指标变化情况
history = model.fit(x_train,y_train,
batch_size= 64,
epochs= 30,
validation_split=0.2 #分割一部分训练数据用于验证
)
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
Train on 569 samples, validate on 143 samples
Epoch 1/30
569/569 [==============================] - 1s 1ms/sample - loss: 1.2484 - AUC: 0.6961 - val_loss: 1.2753 - val_AUC: 0.6402
Epoch 2/30
569/569 [==============================] - 0s 33us/sample - loss: 1.0516 - AUC: 0.6979 - val_loss: 1.0833 - val_AUC: 0.6406
Epoch 3/30
569/569 [==============================] - 0s 32us/sample - loss: 0.8833 - AUC: 0.6969 - val_loss: 0.9255 - val_AUC: 0.6416
Epoch 4/30
569/569 [==============================] - 0s 30us/sample - loss: 0.7475 - AUC: 0.6963 - val_loss: 0.8021 - val_AUC: 0.6411
Epoch 5/30
569/569 [==============================] - 0s 32us/sample - loss: 0.6646 - AUC: 0.6970 - val_loss: 0.7445 - val_AUC: 0.6283
Epoch 6/30
569/569 [==============================] - 0s 35us/sample - loss: 0.6412 - AUC: 0.6784 - val_loss: 0.7099 - val_AUC: 0.6140
Epoch 7/30
569/569 [==============================] - 0s 33us/sample - loss: 0.6238 - AUC: 0.6881 - val_loss: 0.6831 - val_AUC: 0.6316
Epoch 8/30
569/569 [==============================] - 0s 33us/sample - loss: 0.6184 - AUC: 0.7025 - val_loss: 0.6697 - val_AUC: 0.6365
Epoch 9/30
569/569 [==============================] - 0s 32us/sample - loss: 0.6098 - AUC: 0.7138 - val_loss: 0.6652 - val_AUC: 0.6345
Epoch 10/30
569/569 [==============================] - 0s 33us/sample - loss: 0.6039 - AUC: 0.7223 - val_loss: 0.6636 - val_AUC: 0.6434
Epoch 11/30
569/569 [==============================] - 0s 39us/sample - loss: 0.5974 - AUC: 0.7318 - val_loss: 0.6544 - val_AUC: 0.6511
Epoch 12/30
569/569 [==============================] - 0s 37us/sample - loss: 0.5934 - AUC: 0.7375 - val_loss: 0.6490 - val_AUC: 0.6610
Epoch 13/30
569/569 [==============================] - 0s 40us/sample - loss: 0.5893 - AUC: 0.7415 - val_loss: 0.6486 - val_AUC: 0.6578
Epoch 14/30
569/569 [==============================] - 0s 42us/sample - loss: 0.5859 - AUC: 0.7447 - val_loss: 0.6428 - val_AUC: 0.6692
Epoch 15/30
569/569 [==============================] - 0s 42us/sample - loss: 0.5836 - AUC: 0.7511 - val_loss: 0.6374 - val_AUC: 0.6804
Epoch 16/30
569/569 [==============================] - 0s 47us/sample - loss: 0.5774 - AUC: 0.7600 - val_loss: 0.6367 - val_AUC: 0.6828
Epoch 17/30
569/569 [==============================] - 0s 37us/sample - loss: 0.5745 - AUC: 0.7595 - val_loss: 0.6349 - val_AUC: 0.6877
Epoch 18/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5719 - AUC: 0.7696 - val_loss: 0.6288 - val_AUC: 0.7008
Epoch 19/30
569/569 [==============================] - 0s 32us/sample - loss: 0.5676 - AUC: 0.7751 - val_loss: 0.6262 - val_AUC: 0.7071
Epoch 20/30
569/569 [==============================] - 0s 32us/sample - loss: 0.5645 - AUC: 0.7792 - val_loss: 0.6282 - val_AUC: 0.7136
Epoch 21/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5608 - AUC: 0.7853 - val_loss: 0.6232 - val_AUC: 0.7196
Epoch 22/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5596 - AUC: 0.7901 - val_loss: 0.6205 - val_AUC: 0.7226
Epoch 23/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5556 - AUC: 0.7900 - val_loss: 0.6237 - val_AUC: 0.7279
Epoch 24/30
569/569 [==============================] - 0s 32us/sample - loss: 0.5510 - AUC: 0.7980 - val_loss: 0.6190 - val_AUC: 0.7275
Epoch 25/30
569/569 [==============================] - 0s 32us/sample - loss: 0.5494 - AUC: 0.8079 - val_loss: 0.6146 - val_AUC: 0.7333
Epoch 26/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5446 - AUC: 0.8102 - val_loss: 0.6216 - val_AUC: 0.7341
Epoch 27/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5429 - AUC: 0.8101 - val_loss: 0.6133 - val_AUC: 0.7390
Epoch 28/30
569/569 [==============================] - 0s 32us/sample - loss: 0.5379 - AUC: 0.8185 - val_loss: 0.6165 - val_AUC: 0.7356
Epoch 29/30
569/569 [==============================] - 0s 30us/sample - loss: 0.5355 - AUC: 0.8169 - val_loss: 0.6176 - val_AUC: 0.7398
Epoch 30/30
569/569 [==============================] - 0s 33us/sample - loss: 0.5322 - AUC: 0.8237 - val_loss: 0.6082 - val_AUC: 0.7451
四、评估模型
我们首先评估一下模型在训练集和验证集上的效果。
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(history, metric):
train_metrics = history.history[metric] # history.history是一个json数组
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1) # 次数range(1, 31)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(history,"loss")

plot_metric(history,"AUC")

我们再看一下模型在测试集上的效果.
# 输入数据和标签,输出损失和精确度
model.evaluate(x = x_test,y = y_test)
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
179/179 [==============================] - 0s 39us/sample - loss: 0.5423 - AUC: 0.8155
[0.5422718674776941, 0.8154762]
五、使用模型
当使用**predict()**方法进行预测时,返回值是数值,表示样本属于每一个类别的概率。
#预测概率。输入测试数据,输出预测结果
model.predict(x_test[0:10])
#model(tf.constant(x_test[0:10].values,dtype = tf.float32)) #等价写法
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
array([[0.43267167],
[0.45143938],
[0.3366692 ],
[0.7563272 ],
[0.4854551 ],
[0.5545151 ],
[0.23698094],
[0.5242109 ],
[0.50638825],
[0.21195236]], dtype=float32)
当使用**predict_classes()**方法进行预测时,返回的是类别的索引,即该样本所属的类别标签
#预测类别
model.predict_classes(x_test[0:10])
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
array([[0],
[0],
[0],
[1],
[0],
[1],
[0],
[1],
[1],
[0]])
六、保存模型
可以使用Keras方式保存模型,也可以使用TensorFlow原生方式保存。前者仅仅适合使用Python环境恢复模型,后者则可以跨平台进行模型部署。
推荐使用后一种方式进行保存。
1. Keras方式保存
# 保存模型结构及权重
model.save('./data/keras_model.h5')
del model #删除现有模型
# identical to the previous one
model = models.load_model('./data/keras_model.h5')
model.evaluate(x_test,y_test)
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
179/179 [==============================] - 0s 558us/sample - loss: 0.5423 - AUC: 0.8155
[0.5422718674776941, 0.8154762]
# 保存模型结构
json_str = model.to_json()
# 恢复模型结构
model_json = models.model_from_json(json_str)
#保存模型权重
model.save_weights('./data/keras_model_weight.h5')
# 恢复模型结构
model_json = models.model_from_json(json_str)
model_json.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['AUC']
)
# 加载权重
model_json.load_weights('./data/keras_model_weight.h5')
model_json.evaluate(x_test,y_test)
输出结果:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
179/179 [==============================] - 0s 597us/sample - loss: 0.5423 - AUC: 0.8155
[0.5422718674776941, 0.8154762]
2. TensorFlow原生方式保存
# 保存权重,该方式仅仅保存权重张量
model.save_weights('./data/tf_model_weights.ckpt',save_format = "tf")
# 保存模型结构与模型参数到文件,该方式保存的模型具有跨平台性便于部署
model.save('./data/tf_model_savedmodel', save_format="tf")
print('export saved model.')
model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel')
model_loaded.evaluate(x_test,y_test)
输出结果:
WARNING:tensorflow:From D:\Anaconda3\lib\site-packages\tensorflow_core\python\ops\resource_variable_ops.py:1781: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
INFO:tensorflow:Assets written to: ./data/tf_model_savedmodel\assets
export saved model.
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
179/179 [==============================] - 0s 581us/sample - loss: 0.5423 - AUC: 0.8155
[0.5422718674776941, 0.8154762] wechat
wechat- alipay


